区間推定ってなんだろう?信頼区間,信頼度,有意水準って何ですか?AHEADMAP関東支部#7
当ページのリンクには広告が含まれています。

※当ブログはアフィリエイト広告を利用しており,記事にアフィリエイトリンクを含むことがございます
まいど!けいしゅけ(@keisyukeblog)です☆
ツイキャスのテーマで扱った論文の結果はもちろん,参加した感想をレビューします!
今回使われたスライドはYouTubeにアップされています。
このスライド最高やね☆
では,ツイキャスの内容をレビュー&これをキッカケに勉強した内容をまとめていくでっ!!
*ちなみに,以下の動画もとってもわかりやすく,今回のツイキャスの内容を理解するのに役に立つと思われるので貼っておきます☆
目次
AHEADMAP村のリンゴ収穫量から統計学を学的に出してみる!!
例えば,100個の地区から成るAHEADMAP村で収穫できるリンゴの数を予測したいと思ったとき,どうすればいいでしょうか。
母集団と抽出と標本って何ですか?
過去のAHEADMAP村のリンゴ収穫量を調べることができるならば,予測しやすそうでしゅね。
せやね。
AHEADMAP村のリンゴ収穫量はどれくらいか予測するならば,例年の数量を調べることが手っ取り早いし間違いなさそうや。
統計学の用語に変えると,100個の地区から成るAHEADMAP村におけるリンゴ収穫量=母集団(X)と言うねん。
母集団(X)は地区(1)のリンゴ収穫量をX1,地区(2)のリンゴ収穫量をX2,⋯地区(100)のリンゴ収穫量をX100をすべて足したものやね。つまり, X=X1+X2+⋯+X100 や。
1地区あたりどれくらい収穫できるかを計算するなら,母集団を100で割ればいい。数式に置き換えれば,X ÷ 100 や。
これが,統計学の用語では「平均」って言うねん。
ちなみに,それぞれの地区における収穫量(=データ)を標本って言うねんで。
統計学における平均とは,母集団における全ての標本(=データの値)を足して,標本の数(n)で割ったもの
しかしタコちゅけよ,もしもAHEADMAP村全土の収穫量データが無かったらどうする?
100地区みんなが毎年の収穫量を記録してなかったとしたら平均は出されへんで??
えっ!?そんなぁ。
そしたら,データがある地区の収穫量の平均から母集団を推定していくしかないでちゅ。
[/ふきだし]
ナイス!!!
それこそがAHEADMAP関東支部のツイキャスで伝えたかった内容や!
データがある地区の収穫量から,地区(1)・地区(26)・地区(52)・地区(79)・地区(97)5つを選ぶとしよう。
統計学の用語に置き換えよう。母集団から5つの標本を抽出するんや。
抽出した標本の平均を出すことで,母集団の値をなんとなぁく予測することは可能っぽくないか?
例えば,5地区のリンゴ収穫量が例年平均15万個だったとする。抽出された5地区の平均で,1地区あたり15万個収穫できるんやから,100地区あるAHEADMAP村の収穫量(母集団)は1500万個になるだろうってね。
期待値って何ですか?
確かにそうでちゅね。
しかし先生,この計算って正確な収穫量を出せないでちゅよね。
だって,5つの地区で平均15万個収穫できるのは例年データから予測した数値でちゅ。どのくらいの確率(p)で15万個のりんごが収穫できるか?って確率を加味して考える必要が出てくるんじゃ・・・。
(こやつ天才か?言おうとしてたことを先取りされちゃったぞ)
お,おう。
タコちゅけさん,ええと・・・。そうやね。(うろたえたぁっ!「さん」とか付けてもうたぁぁぁ!!)
その通りだよ。(何故に標準語!?落ち着け,けいしゅけ。)
それが,期待値ってヤツや!
けいしゅけが唐突に発した統計用語「期待値」ってなんでしょう?
これまでの説明によれば,AHEADMAP村のリンゴ収穫量を予測するにあたって,5つの地区の例年の収穫量をデータとして使おうとしています。しかし,例年のデータ通りに今年も収穫できるとは限らないですよね。つまり,例年通りの数量を収穫できる確率を加味する必要性が生じます。この確率を加味したデータを期待値と言います。
・・・さすがにざっくりすぎるので,期待値の定義を記しましょう。
〘数〙 確率変数 x が値 x 1 , x 2 … x n を確率 p 1 , p 2 … p n でとる時,x 1p 1+x 2p 2+…+x n p n をいう。例えば,くじが全部で一〇〇本あって,当たりくじは一万円が五本,五万円が二本だけならば,くじを一本ひく時の期待値は一五〇〇円である。
出典 三省堂/大辞林 第三版
よってタコちゅけ,さっきの説明をもう一度言い直すわ。
5地区のリンゴ収穫量が例年平均15万個だったとする。
すると今年の収穫量の期待値は,1地区あたり15万個や。せやから100地区あるAHEADMAP村の収穫量(母集団)の期待値は1500万個っちゅうこっちゃな。
区間推定と信頼区間,信頼度,有意水準って何ですか??
リンゴの収穫量だけでもたっくさんの統計用語がわかっちゃいましゅね!
すごいスゴーーーーーい!!
ところで先生,リンゴの収穫量って「〇万個」ってピンポイントの数値が出せるものなんでちゅか?
(この子,統計学めっちゃ知ってるんじゃないの?)
鋭いな,タコちゅけ。
まさに,チミが言うてるのは「区間推定」の事やねん。
あー!待て待て,区間推定って何ですか?とか聞きだすやろ?そうやろ?そうに決まっている!
だから答えるわ。
区間推定というのは・・・
ふむふむ。
区間推定は,母集団の従う分布が正規分布であると仮定できるときに,標本から得られた値を使ってある区間でもって母平均などの母数を推定する方法です。
このときの区間のことを「信頼区間」といいます。論文などでは略語表記として「CI」が用いられます。
統計WEBより引用(強調は筆者による)
先生が以前に記事にしてはった臨床試験の結果に出てくるハザード比や95%信頼区間の意味って何?の信頼区間ってこの区間推定から来ているんでちゅねぇ。
食い気味にきたね,タコちゅけ・・・。
しかし正解や!
そして,区間推定というのはある程度の区間を設定して母集団の数値や平均値などを推定するわけやけど,統計学では「ある程度」を95%で設定しているねん。(なんで95%なの?というと「なんとなく」なんよ。)
母平均の区間推定では「95%信頼区間(95%CI)」を求めることが多いですが,これは「母集団から標本を取ってきて,その標本平均から母平均の95%信頼区間を求める,という作業を100回やったときに,95回はその区間の中に母平均が含まれる」ということを意味します。
また,95%信頼区間以外に「99%信頼区間」や「90%信頼区間」といった区間を求めることもあります。
この95%や99%,90%のような,ある区間に母数が含まれる確率のことを「信頼係数」あるいは「信頼度」といいます。
統計WEBより引用(強調は筆者による)
ちなみに天気予防の台風の進路予測円,これが70%信頼区間です。
ちなみに,この信頼度からはずれる境界線に名前がつけられているで。
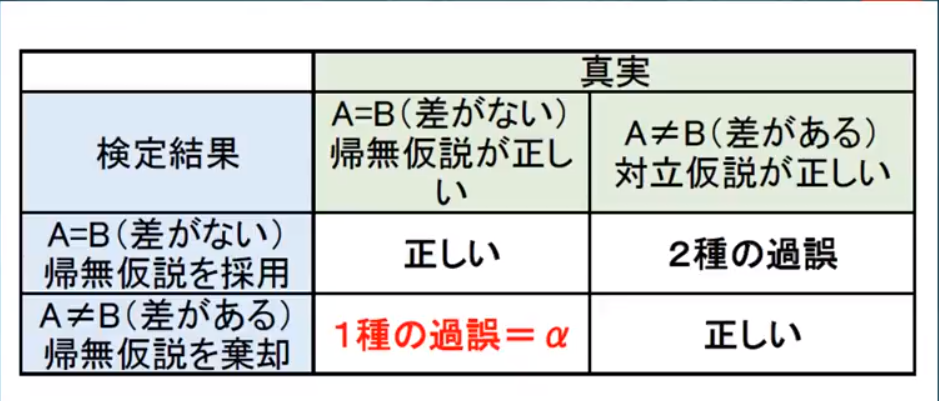
それが「有意水準」ってヤツや。1-信頼度=有意水準(α)で表すことができる。
(よっしゃ!タコちゅけを満足させることに成功!!)
[/ふきだし]









 けいしゅけ
けいしゅけ タコちゅけ
タコちゅけ タコちゅけ
タコちゅけ けいしゅけ
けいしゅけ タコちゅけ
タコちゅけ








記事の感想など,ひとこと頂けますか?